import torch
from torch import nn
import torch.nn.functional as FBasic encoder-decoder architecture encodes the input sequence into a fixed-length context vector, which is a performance bottleneck according to Bahdanau et al. [1]. They proposed a attention mechanism to improve the performance of RNN encoder-decoder models by helping the decoder to focus on the most relevant parts of the input sequence when generating the output sequence.
How does the attention mechanism work?
The purpose of the attention is to compute a context vector for the decoder to generate output sequence. The whole process is done in 3 steps, as illustrated in the following figure [1]:
- the encoder computes annotations for every word in the input sequence.
- the decode use an alignment model to compute attention scores based on the annotations from the encoder
- finally, the decoder compute the context vector using the attention scores and the annotations
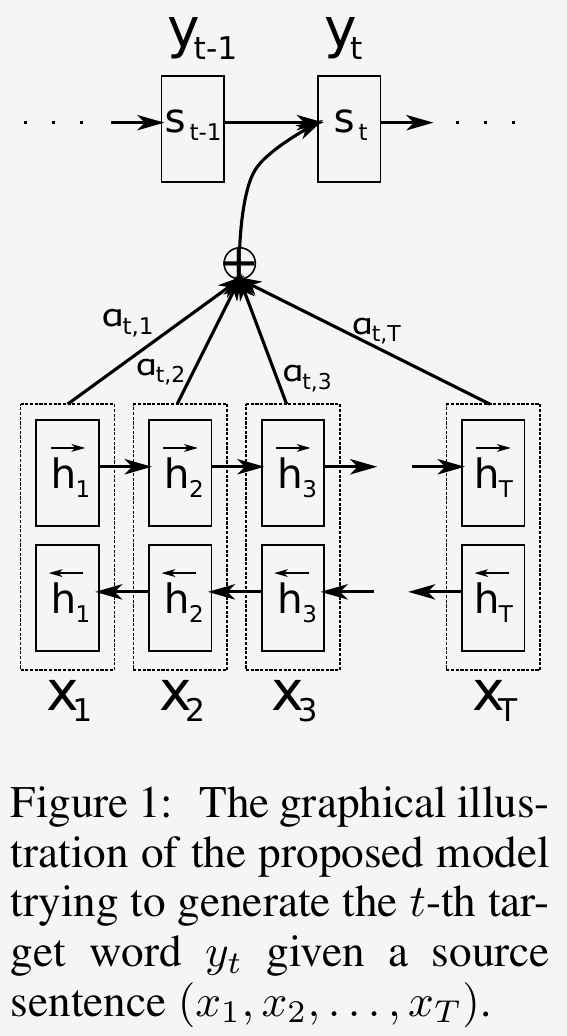
Image source: Bahdanau et al. [1]
Step 1: compute annotations
The encoder uses a bidirectional RNN (BiRNN) so that the annotation of each word \(j\) summarizes both the preceding and following words. The results are a forward hidden state \(\overrightarrow{h_j}\) and a backward hidden state \(\overleftarrow{h_j}\), which are concatenated to form the annotation: \(h_j=\left[\begin{array}{c}\overrightarrow{h}_j \\ \overleftarrow{h}_j\end{array}\right]\)
step 2: compute attention scores
The decoder uses an alignment model to compute attention scores. The authors chose a single-layer MLP as the alignment model, \[ a(s_{i-1}, h_j) = v_a^\intercal\ tanh(W_a s_{i-1} + U_a h_j) \] \(W_a\), \(U_a\) and \(v_a\) are weight matrices. \(h_j\) is the \(j\)-th annotation from the source sequence. \(s_{i-1}\) is the decoder state at time \(i-1\).
At time \(i\), given the \(j\)-th annotation \(h_j\), the attention score \(e_{ij}\) is computed using the previous decoder state \(s_{i-1}\), \[ e_{ij} = a(s_{i-1}, h_j) \]
step 3: compute context vector
A context vector is a weighted sum of annotations. At time \(i\), the context vector can be defined as, \[ c_i = \sum_{j=1}^{T_x} \alpha_{ij}h_j \] Here, \(T_x\) is the length of the source sequence. The weights \(\alpha_{ij}\) are the results of appying softmax to the attention scores from step 2.
Implement Bahdanau Attention using PyTorch
class BahdanauAttention(nn.Module):
def __init__(self, enc_hidden_dim, dec_hidden_dim):
super().__init__()
self.Wa = nn.Linear(dec_hidden_dim, dec_hidden_dim)
self.Ua = nn.Linear(enc_hidden_dim*2, dec_hidden_dim)
self.va = nn.Linear(dec_hidden_dim, 1)
def forward(self, s_prev, hs):
"""
s_prev: previous decoder hidden state, size: (batch_size, dec_hidden_dim)
hs: encoder annotations, size: (batch_size, src_seq_length, enc_hidden_dim*2)
"""
attn_scores = self.va(
torch.tanh(
self.Wa(s_prev).unsqueeze(1) + self.Ua(hs) # (batch_size, src_seq_length, dec_hidden_dim)
)
).squeeze(-1) # (batch_size, src_seq_length)
weights = F.softmax(attn_scores, dim=-1) # (batch_size, src_seq_length)
context = torch.bmm(weights.unsqueeze(1), hs).squeeze(1) # (batch_size, enc_hidden_dim*2)
return context, weightsReferences
[1]
D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate.” 2016. Available: https://arxiv.org/abs/1409.0473